Was ist interner Duplicate Content?
Nun, was ist Duplicate Content überhaupt? Interner Duplicate Content kann eigentlich ganz einfach beschrieben werden:
(1) Jede Seite einer Website, die unter mehr als einer URL aufrufbar ist, stellt Duplicate Content dar.
Ganz einfach oder? – Nun ja, leider ist es dann doch nicht soo einfach. Da kommt dann noch ein wenig dabei, nämlich potentieller Duplicate Content.
(2) Jede sortierte Liste ist potentieller Duplicate Content.
Gut, einen Schritt weiter. Fehlt aber noch ein Punkt.
(3) Jede ähnliche Seite ist potentieller Duplicate Content.
Jetzt sind wir soweit vollständig, was internen DC angeht. Ich will ein paar Beispiele geben, die verdeutlichen, was dahinter steckt. Ich will keine Seiten zeigen, die es vielleicht machen, daher müsst Ihr mit einer gewissen Abstraktion leben.
1. Gleiche Seite auf verschiedenen URLs
- https://www.beispiel.de
- https://www.beispiel.d?IchBinEinParameter
Das kann vor allem fies werden, wenn Ihr Affiliate-Links von außen reinkommen habt, die von Euch natürlich gecrawlt werden wollen. Es gibt sicherlich einige Leute, die mit Affiliate-Links versuchen, Linkpower aufzubauen – mit parametrisierten URLs funktioniert das leider aber eher mit entgegengesetztem Effekt.
Probiert es aus, hängt an eine Eurer Seiten einen beliebigen Parameter an – voila. DC.
2. Sortierte Listen
Stellt Euch vor, Ihr habt einen Shop und verkauft Rucksäcke. Nun habt Ihr eine wunderschöne Liste mit Rucksäcken, die der User mit den tollsten Parametern und Wünschen sortieren kann, z.B. nach dem Preis. Das macht er auch fleißig. Ebenso wie der Googlebot. Klick, klick, klick.
Nun habt Ihr vielleicht nur eine Seite mit Rucksäcken, weil das echt super seltene Teile sind. Meint Ihr, Google würde nicht merken, dass der Content auf der Seite einfach nur irgendwie gedreht ist, aber genau die gleichen Inhalte hat?
Wenn Ihr das denkt, dann produziert Ihr reinsten Gewissens den schönsten DC.
3. Ähnlicher Content
Ein wenig ähnlich gelagert wie die Sache mit der Sortierung, aber doch anders. Ihr habt eine Seite mit – ach, sagen wir mal Rucksäcken, diesmal aber eine Detailseite. Der User kann hier Farben auswählen und Ihr liefert eine neue URL aus, weil vielleicht wird der rote Rucksack ja verlinkt und der blaue auch (das wäre toll)?
Nunja. Vielleicht fällt Euch auf, dass sich auf der Seite kaum Inhalt ändert. Der Rucksack wird blau (denn Ihr habt nen wirklich coolen Shop) und die Überschrift ändert sich vielleicht.die Seite sieht ja wirklich ganz anders aus als vorher!
Nun, zählt mal Eure Wörter zusammen, Ihr habt mit Sicherheit eine Ähnlichkeit von 99%. Glaubt Ihr das reicht? – DC.

Die häufigsten Fälle von internem DC
Es bedarf einer gewissen Nase für internen Duplicate Content, gerade weil die meisten Leute ihn nicht schlimm finden und denken “Google wirds schon richten und erkennen”. Denkste. Wie wir mit Duplicate Content umgehen und ihn steuern bzw. entfernen, das kommt weiter unten noch.
Hier will ich aber kurz Hilfestellung zur Erkennung leisten – schaut einfach mal, ob Ihr auf Eurer Seite das ein oder andere Problemchen findet. Ich bleibe bewusst hier auch mal bei WordPress-Themen, weil die Blogosphäre im Gesamten betreffen, die Probleme sind aber transferierbar.
- Kanonische URL: Ist Eure Domain mit https://www.domain.de und mit https://domain.de, vielleicht noch mit https://domain.de/index.php aufrufbar?
- IP als Komplett-DC: Ursächlich technisch kann es auch sein, wenn Eure IP aus Gründen in den Index gelangt. Heise, Golem und einige andere größere Seiten haben dieses Problem. Man muss es nur erkennen und das ist meist zufällig. Das echte Problem ist aber: der komplette Inhalt der Domain wird gespiegelt bzw. dupliziert. Nicht gut.
- Unnütze Parameter: Klickt mal bei Eurem WordPress-Blog einfach auf die Suche, ohne ein Suchwort einzugeben. Na? Genau. Domain-DC/Startseiten-DC (das Schlimmste was passieren kann) – und Google klickt auf Buttons, das wissen wir.
- Zugänglichmachung: Euer Blog benutzt Tags, Kategorien, Datumsarchive, alles, was geht. Leider ist das alles potentieller DC. Entscheidet Euch für eine Version von Listen, die Ihr indexieren lassen wollt.
- Artikelseiten unter verschiedenen URLs: Besonders ein WordPress-Problem – Ihr könnt jede URL in Eurem WP-Blog manipulieren. Das macht man natürlich nicht freiwillig, aber vielleicht ändert Ihr unbewusst mal die Kategorie eines Beitrages. Zack, habt Ihr zwei valide URLs, denn – probiert’s mal aus: Ihr könnt den Kategorienamen in der URL durch eine andere Kategorie Eures Blogs ersetzen. Ein falscher Link genügt und Ihr habt DC.
- Sortierungen und Auswahlen: Die Beispiele von weiter oben. Sortierte Listen und parametrisierte Artikel/Detailseiten sind DC.
Wenn Ihr über Eure Seiten guckt, werdet Ihr mit Sicherheit irgendwo DC finden, ganz sicher ist keine Seite hier perfekt und sei es wegen technischer Restriktionen (CMS, Blogsystem etc.). Wenn ihr allerdings wisst, wie Ihr DC erkennt, habt Ihr den ersten wirklich wichtigen Schritt getan, ihn auch zu vermeiden.
Tipps und Tricks zur Erkennung von DC
Gerade die Erkennung von ähnlichen Seiten als Duplicate Content kann einem zu schaffen machen. Ihr müsst Euch generell Eure Navigation, den Footer und den ganzen Kram wegdenken, denn das kann Google auch ganz gut. Dann vergleicht Ihr die übrigen Text- und Bild-Elemente des eigentlichen Inhalts der beiden in Frage kommenden Seiten. Wenn Ihr einen Wert über 80% erreicht, seid Ihr auf der sicheren Seite, dass Ihr gerade DC produziert habt. (Es gibt hier auch Tools, wie Siteliner, die Euch so was ausrechnen, mit Verstand gehts aber am einfachsten)
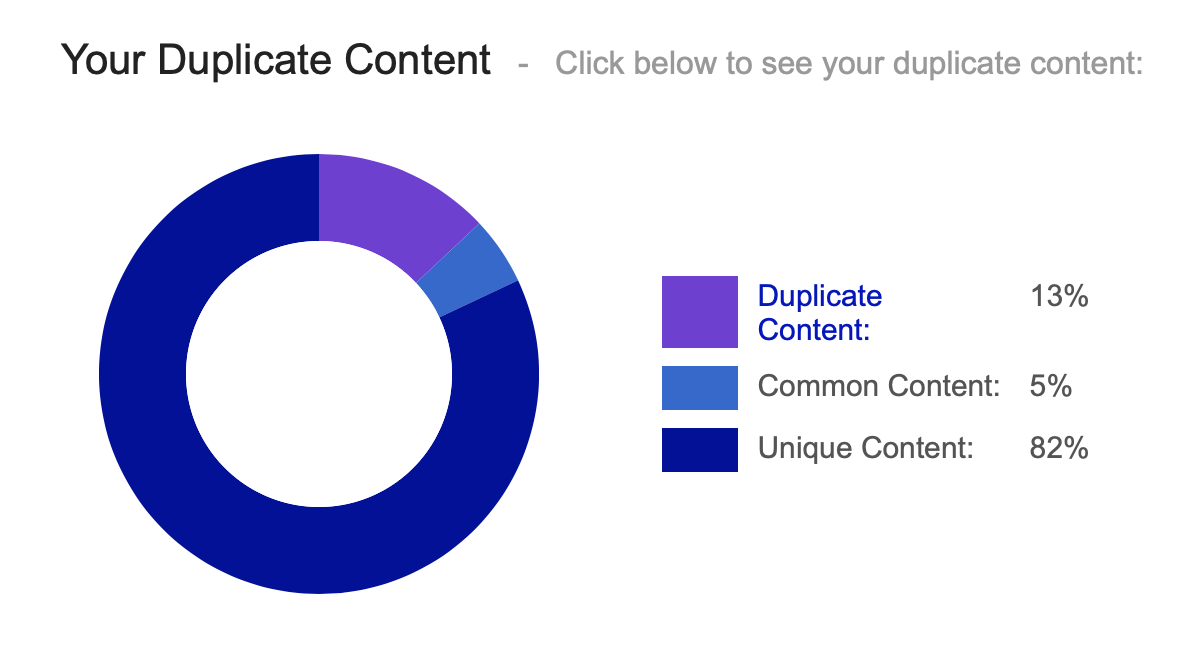
Nutzt Google! Leider ist für diesen Tipp das Kind wohl schon in den Brunnen gefallen. Macht eine Site-Abfrage Eurer Seite und grenzt Sie soweit ein, dass Ihr eine solide Anzahl von Seiten ausgegeben bekommen müsstet. Google indexiert nun das nicht, was als Duplikat (Near Duplicate) gewertet werden könnte, bzw. sehr ähnlich anderen Seiten Eurer Website ist, ab. Durch die Abfrage „site:deineseite.de/“ können Sie alle Seiten, die von Google geprüft und indexiert wurden, sehen.

Geht einfach mal davon aus, dass alles was dort fehlt und nicht allzu neu ist, potentiell ein kleineres Problem hat.
Was ist externer Duplicate Content?
Externer Duplicate Content bezieht sich auf duplizierte Inhalte außerhalb der eigenen Domain. Das kann sowohl im eigenen Netzwerk, als auch auf Websites der Konkurrenz der Fall sein. Nach meiner Erfahrung wird auch doppelter Inhalt auf Subdomains des eigenen Projektes als externer Duplicate Content gewertet.
“Meine Website sieht doch ganz anders aus, als die des Konkurrenten, ich habe einen anderen Header und Footer und andere Seitenelemente!”
Wer so an die Analyse von externem DC herangeht, der hat verloren und genau derjenige sollte sich den folgenden Hinweis sehr zu Herzen nehmen.
- Google und andere Suchmaschinen erkennen seitenweit wiederkehrende Strukturen wie Navigationselemente, Footerbereiche oder Sidebar-Elemente auf Websites.
- Das heisst, Google kann sehr wohl unterscheiden, was Inhalt und was Ausstattung ist.
Wichtig ist also wirklich nur die Betrachtung des Inhalts (im besten Falle das, was unterhalb der H1 steht). Nun, wer sich an die Einteilung des ersten Teils (Interner Duplicate Content) erinnert, der wird die folgende Aufzählung in Teilen wieder erkennen.
1. Gleiche Inhalte auf verschiedenen Domains ist externer Duplicate Content
Das ist klar und kann jeder verstehen.
2. Ähnliche Inhalte auf verschiedenen Domains sind potentieller Duplicate Content
Auch das ist, wenn wir uns die Ergebnisse des ersten Teils zum internen DC vor Augen halten deutlich. Sortierungen, Listen, Ergebnisse, das alles kann DC bedeuten – wie intern so auch extern.
3. Eure Domain ist komplett dupliziert oder gespiegelt
Das ist bei weitem die fieseste aller Angelegenheiten. Wenn die Startseite eures Produktes als DC erkannt wird oder dupliziert im Internet auftaucht, solltet Ihr wirklich schnell versuchen, die Duplikate zu beseitigen. Wie Ihr vorgeht, um solche Fälle aufzudecken seht Ihr weiter unten.
Wie reagieren Suchmaschinen auf Duplicate Content?
Es gibt zwei Möglichkeiten, wie die Suchmaschinen Google, Bing, etc. auf den Duplicate Content reagieren. Entweder die duplizierten Inhalte werden von den Suchmaschinen „zusammengelegt“, oder es kann passieren, dass eine Seite, die sich kopierter Texte bedient, aus dem Index ausgeschlossen wird. Verlinkt man den gleichen Inhalt mit verschiedenen URLs, verschlechtert sich das Suchergebnis.
Fachleute aus der Suchmaschinenoptimierung achten deshalb strikt darauf, dass nur Unique Content verwendet wird. Es gibt Tools, die fertige Texte auf ihre Einzigartigkeit überprüfen – dazu später mehr. Allerdings reicht es beispielsweise auch, die erste Passage eines Beitrags in Google einzutippen und die Suche zu starten. Findet sich ein ähnlicher Text im World Wide Web, so wird das Ergebnis das auch anzeigen.
Die Texter, die den Auftrag erhalten, Content zu erstellen, sollten eigentlich darauf achten, beziehungsweise überprüfen, ob unique gewährleistet werden kann, oder nicht. Eine Erklärung auf der Rechnung, dass alle Texte aus eigenen Ideen verfasst und nicht abgekupfert wurden, wird von vielen Agenturen in der Suchmaschinenoptimierung verlangt. Es wäre leichtsinnig, Content abzuliefern, der nicht gegengecheckt wurde.
Wem gehört der originale Content?
Wenn die Suchmaschinen Duplicate Content finden, müssen sie entscheiden, wem der originale Content gehört. Das machen sie nach algorithmischen Vorlagen, die im Grunde einfach zu verstehen sind, allerdings im Outcome nicht immer richtig oder eindeutig sind.
- Fingerprint/Timestamp: Gefundener Content bekommt im Regelfall eine Art Versionierung von den Suchmaschinen. Das kann man auch Fingerprint nennen. Es wird vermerkt (wie eigentlich alles immer überall vermerkt wird), wann der Content wo gefunden wurde. Wenn dieser Fingerprint festgelegt wurde, bekommt die Seite, die als erstes mit dem Content identifiziert wurde in der Regel den Content als Original zugesprochen.
- Google News: Ich bin in diesem Fall kein Experte, daher kann ich nur oberflächlich schreiben. Bei News sieht man aber deutlich, dass das Prinzip gilt: First Come, First Serve. Die meisten Zeitungen kommen mit DPA-Meldungen daher, die in der Regel, ebenso wie Pressemitteilungen (Achtung bei Artikelverzeichnissen, Presseverzeichnissen etc.) DC sind.
- Diebstahl/Content-Klau: Durchaus problematisch ist Content-Diebstahl. Das können Texte sein oder Bilder. Es wird ja nicht seit gestern erst darüber berichtet, dass Content geklaut und auf anderen Seiten 1 zu 1 veröffentlicht wird. Das ist sehr ärgerlich, aber leider nicht immer vermeidbar. Wenn zudem die fremde Seite außerhalb des deutschen Rechtsraumes liegt, könnt Ihr selbst rechtlich nicht viel dagegen machen. Kleine technische Dinge werde ich aber im nächsten Teil “Duplicate Content vermeiden” erläutern.
- Trust und Domainstärke: Sowohl bei Fingerprint als auch bei geklautem Inhalt gilt zu einem guten Teil der Trust bzw. die Stärke einer Domain als Faktor für die Originalität des Content. Ein kleines Beispiel: Eure Domain mit dem Originalinhalt ist 3 Jahre alt und hat verschiedene Themenbereiche. Jetzt kommt einer daher (vielleicht Ihr selbst) und übernimmt diesen Content auf einer Domain, die vielleicht 6 Jahre alt ist, mehr Links hat und sich nur mit diesem Thema beschäftigt. Der Content wird mit Wahrscheinlichkeit dieser Domain zugerechnet und Euer eigener Traffic kracht ab.
Wie erkenne/finde ich externen Duplicate Content?
1. Gleiche Inhalte auf verschiedenen Domains
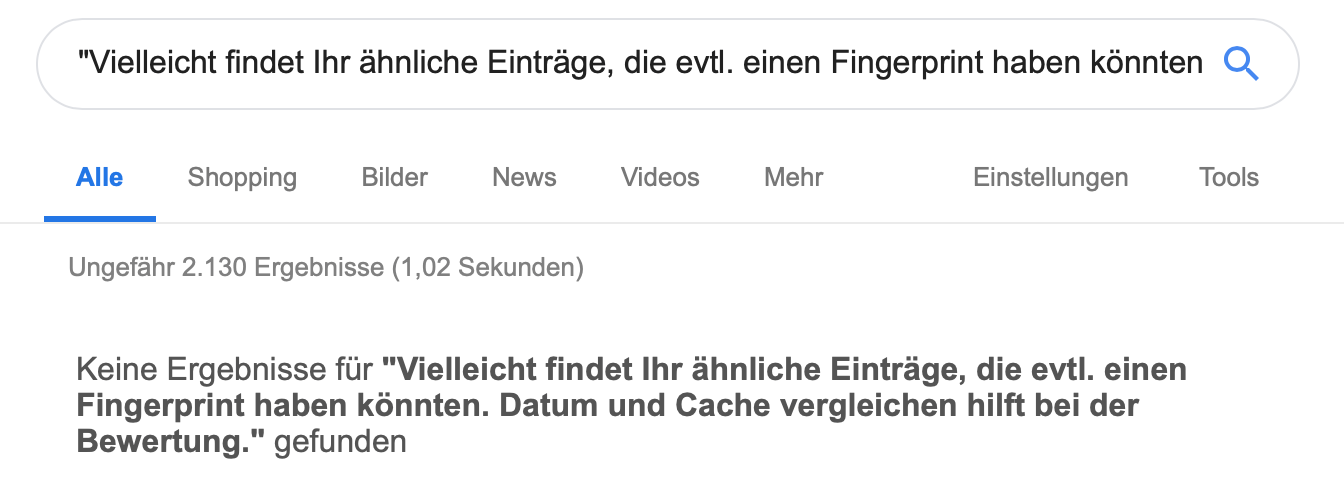
Solche Fälle kann man sehr gut mit einer Quotation-Abfrage bei Google machen. Nehmt Euch einfach einen Teil des Inhalts Eurer Seite und kopiert in “in Anführungsstrichen” bei Google in die Suchbox. Vielleicht findet Ihr ähnliche Einträge, die evtl. einen Fingerprint haben könnten. Datum und Cache vergleichen hilft bei der Bewertung. Auch hier gibt es Tools, die das Aufspüren von geklauten Bildern oder Text möglich machen.
2. Ähnliche Inhalte auf verschiedenen Domains
Das typische Zeitungen/DPA-Problem. Hier kann ich wirklich nicht viel zu sagen, weil ich gerade im News-Bereich einige Lücken habe. Generell gilt aber wie beim internen DC: Je höher die Vergleichbarkeit der Textelemente, desto eher handelt es sich um DC.
3. Duplizierung der Domain oder Startseite
Das ist der Supergau und Ihr solltet generell aufpassen, dass Euch keine Duplikate Eurer Startseite in den Index gelangen. Manchmal werden Domains gespiegelt, manchmal passieren solche Dinge, weil Ihr eine IP im Index habt (auch das ist externer DC) und somit Eure komplette Domain spiegelt. Je mehr Trust und je älter das Projekt ist, desto eher könnt Ihr bei solchen Fällen allerdings auch gut wegkommen. Die Telekom hat massig von Domains, die den gleichen Content haben, Heise und ähnlich Projekte sind mit IPs im Index verteten und es schadet (noch nicht). Bei kleineren Projekten kann das aber durchaus schädlich sein.
Ihr könnt solch eine Duplizierung entdecken, indem Ihr den Titel Eurer Startseite bei Google via „Intitle-Abfrage“ sucht und entsprechende gleiche Seiten genauer unter die Lupe nehmt. Ich habe über dieses Problem bereits ausführlicher geschrieben und auch, was Ihr tun solltet, wenn so etwas passiert.
Internen Duplicate Content verhindern
Wir hatten etwas über gleiche Seiten durch URL-Verwirrung gelesen, , ebenso über ähnliche Seiten und sortierte Listen. Alle dies war bzgl. der Definition, wie wir sie Google in den Mund legen als DC deklariert worden. Diesen gilt es nun zu verhindern und wir haben einige Mittel, die wir nutzen können.
Noindex
Meiner Meinung nach ist Noindex das kolumbus’sche Ei der SEO. Alles, was Ihr zweifelhaft findet, alles, was Euch nicht gefällt, alles, was Ihr wirklich für DC haltet – knallt ein schönes „Noindex“-Atrribut drauf. Das tolle: Links, die evtl. eingehen werden anteilig wenigstens weiter verteilt. Daher immer schön an die interne Verlinkung denken. Für WordPress gibt es da sehr schöne Tools, wie robots-meta von Yoast oder All In One SEO.
Robots.txt
Mit Eurer robots.txt solltet Ihr vorsichtig umgehen. Denkt immer daran: Alles, was Ihr mittels robots.txt aussperrt, wird vom Bot nicht mehr gefunden. Ihr könnt Euch also ganz schnell den Linkjuice und auch die Crawlability abdrehen. Google findet die Seiten, die von robots.txt gesperrt sind natürlich, denn erst beim Aufrufen weiß der Bot, welche URL die Seite hat.
Grundsätzlich haben in der robots.txt daher keine Seiten etwas verloren, die potentiell verlinkt werden könnten. Einzelne Seiten freigeben könnt Ihr z.B. via Sitemap (Xing macht das ganz gut, da könnt Ihrs abgucken) oder Wildcards. Zur Prüfung empfehle ich aber unbedingt, in den Google Webmastertools die Richtigkeit nachzuhalten, denn eigentlich sind die Wildcards oder auch “allow” in der robots.txt nicht vorgesehen, die benötigt man aber öfter und sind sehr hilfreich.
Nofollow
Rel-nofollow ist absolut nicht hilfreich, um Duplicate Content zu reduzieren. Das einzige, was passiert, ist, dass Eure Links keinen Ankertext und keine Juice übergeben. Die Indexierung könnt Ihr mit nofollow nicht steuern. Schlagt Euch das aus dem Kopf. Etwas anderes ist meta-nofollow. Laut Definition sollen hier wirklich Links nicht abgegangen werden. Ich habe gerade keinen Test, glaube aber nicht, dass dem so ist.
Canonical-Tag
Ich will hier keine Empfehlung geben, ob das was taugt, dazu ist es noch zu früh. Im Grunde finde ich den Tag für verschiedene Dinge ganz geeignet. Das hat vor allem mit dem Umleiten von Linkpower von Noindex-Seiten zu tun, die man nicht 301en kann. Ich denke allerdings, dass wir uns hüten sollten, einen zweiten nofollow- oder PageRank-Sculpting-Hype auszulösen. Das Tag ist zu aufwändig, als dass es wirklich sinnvoll eingesetzt werden könnte. Dass es da unterschiedliche Meinungen gibt, brauche ich aber wohl nicht sagen. Testen ist angesagt. Vor allem aber gilt:
Legt eure Seitenstruktur weise und profund fest, dann braucht Ihr weder Sculpting noch Canonical
(Tracking per) URL-Parameter vermeiden
Oftmals passiert im Web folgendes: Der Marketing Manager möchte Werbung machen, startet Affiliate-Programm und freut sich über die gleichzeitig eingehenden Links. Schade nur, dass die zum Tracking alle internen DC erzeugen, weil sie mit Parameter ausgeliefert werden (z.B. domain.de?afflink=123). Es gibt hier verschiedene Lösungen: Cookies einsetzen und damit tracken, die Parameter noindex setzen oder einfach nicht tracken.
SEOmoz zeigte noch eine feine Idee: Hash (Raute) anstatt ?-Parameter benutzen (also domain.de#afflink=123). Wen das näher interessiert: Hier gibts das Whiteboard-Friday-Video und einen nettes Shopbeispiel, wie man Paginierung eben mit # darstellen kann. Der Clou: # wird von Google nicht bewertet und all die nette Linkpower fließt der Originalseite zu.
Probleme gibts aber auch, die sind im SEOmoz-Post nachzulesen. Achtung: Wenn Ihr mit den Paginierungen Detailseiten zugänglich machen wollt, passt auf, dass nicht zuviele Links auf einer Seite stehen (die Menge müsst Ihr selbst rausfinden, dieser Blog dürfte ca. 100 vertragen). Der Beispiel-Shop hatte keine Details und fährt daher sehr gut mit dem Programm.
Nun, Mittel sind eines, ein paar Beispiele sind natürlich viel viel cooler. Also los.
Kategoriensystematik in WordPress
Nun, ich hatte das kurz bereits angesprochen. Auch in SEO-Blogs sieht man häufig immer die gleichen Systematiken: Navigation bzw. Zugänglichmachung der Detailseiten via: Tags, Autoren-Archive, Kategorienarchive, Datumsarchive. Was wir aus der Fingerprint-Systematik wissen ist, dass ein Teaser fast so gut ist, wie eine Detailseite. Umso unverständlicher ist es für mich, das Ganze Gerödel an Kategorien und Tags und allem drum und dran auch noch indexieren zu lassen.

Mit noindex wäre das doch so einfach zu umgehen und schließlich sind ja die Detailseiten das, was wichtig sein sollte, nicht irgendeine Kategorie. Richtig schwieirg finde ich in diesem Zusammenhang dann Systeme oder Plugins, die automatisch Buzzwords auf Tag-Seiten verlinken. Furchtbar.
Nur um das klarzustellen: Es gibt mit Sicherheit gute Gründe, dies oder das indexieren zu lassen, in manchen Fällen können Kategorien sicher auch besser funktionieren als Details. Was allerdings sehr sorgfältig geprüft werden muss, ist der Einsatz mehrerer dieser Archive gleichzeitig. Das gleiche gilt im Übrigen auch für indexierbare (Full)feeds.
Vor allem die Indexierung von Tag-Seiten solltet Ihr genau prüfen. Wenn Sie im Durchschnitt 4-6 Tags pro Beitrag habe, heißt das Sie würden potentiell 5 neue Seiten pro Beitrag in den Index kippen. Das ist zuviel.
Doppelte URLs, Parameter
Lasst Eure Suchseiten nicht indexieren und leitet Eure Seite meinblog.de?s= auf Eure Hauptseite um, denn Google drückt mit Sicherheit mal einen Button. Achtet vor allem aber auchdarauf, dass Ihr Eure Beiträge korrekt anlegt. Ein großes Problem von WordPress ist es, dass jeder Beitrag in jeder Kategorie aufrufbar ist. Das macht Euch potentiell von außen angreifbar.
Wenn Ihr einen Beitrag umzieht, oder generell Eure Kategoriensystematik ändern wollt, solltet Ihr in jedem Fall ein Plugin wie Redirection verwenden. Es gilt aber immer: Vorher überlegen, denn ein 301 kann Euch die Linkpower, die Ihr auf dem Original habt nie ganz zurückgeben.
Externen Duplicate Content verhindern
Externen DC zu vermeiden ist ungleich schwieriger, als internen DC zu beeinflussen, da zumeist Euer Einfluss auf die Seite, die den externen Duplicate Content bereitstellt außerhalb Eures Einflussbereiches liegt. Dennoch kann man mit ein paar grundlegenden und einfachen Regeln gut vorarbeiten, um Duplicate Content in vielen Fällen bereits vor der Entstehung wirksam zu vermeiden.
Kooperationen organisieren
Kooperationspartner, die Euren Content aufgrund von was auch immer ausspielen (Content-Tausch, Abspielfläche, Verkauf etc.) sollten den Content mindestens auf noindex setzen. Wenn ein Ausschluss des Crawlings durch die robots.txt machbar ist, sollte auch das getan werden. Externe Kooperationen können gefährlich sein, was DC angeht. Ihr solltet bereits beim Denken daran ganz heftig mit der noindex-Fahne wedeln.
Unique Content
Beispiel: DPA-Meldungen. Wie oft lest Ihr im Netz das Gleiche. Und mit Sicherheit möchte jeder dieser Publisher im Netz gefunden werden. Da hilft aber meistens und leider nur eins: Wenn Ihr nicht absolut am Schnellsten publizieren könnt, dann müsst Ihr wohl oder übel auf echte redaktionelle Mittel zurückgreifen und den Text verändern.
Fingerprints
Was intern bei Kategorie-Listen möglich ist, das kann natürlich auch extern passieren. Da ist es meist nur schlimmer, da sich Google den Besitzer des ursprünglichen Fingerprints selbst aussucht. Was hier hilft ist nur Unique Content. Wenn Ihr teilweise duplizierten Content habt, verändert ihn, wenn es Eure Zeit zulässt und Ihr einen positiven ROI erwartet. Wenn beides nicht zutrifft, macht Eure Seite dicht und überlegt Euch eine neue Aufgabe für Euren Webserver.
Fazit zum Duplicate Content
Wie Ihr seht, ist Noindex wirklich einer meiner Lieblinge. Das Meta-Tag ist ein mächtiges Werkzeug, wenn man es richtig einsetzt. Es gibt mit Sicherheit noch weitere Möglichkeiten, DC zu vermeiden, vielleicht habe ich auch eine echt wichtige vergesse. Ihr dürft daher gerne und fleißig kommentieren (sofern Ihr es bis hierher geschafft habt, durchzuhalten).