What is internal duplicate content?
Well, what is Duplicate Content at all? Internal Duplicate Content can actually be described quite simply:
(1) Any page of a website that is listed under more than one URL is callable, represents Duplicate Content dar.
Ganz einfach oder? – Nun ja, leider ist es dann doch nicht soo einfach. Da kommt dann noch ein wenig dabei, nämlich potentieller Duplicate Content.
(2) Any sorted list is potential duplicate content.
Good, one step further. But there is still one point missing.
(3) Every similar page is potential duplicate content.
We are now complete as far as internal DC is concerned. I want to give a few examples to illustrate what's behind it. I don't want to show any sites that might do it, so you'll have to live with a certain degree of abstraction.
1. same page on different URLs
- https://www.beispiel.de
- https://www.beispiel.d?IchBinEinParameter
This can be particularly nasty if you have affiliate links coming in from outside, which of course want to be crawled by you. There are certainly some people who try to build up link power with affiliate links - but with parameterized URLs this unfortunately tends to have the opposite effect.
Try it out, attach any parameter to one of your pages - voila. DC.
2. sorted lists
Imagine you have a store and sell backpacks. Now you have a wonderful list of backpacks that the user can sort by the most amazing parameters and wishes, e.g. by price. He does this diligently. Just like the Googlebot. Click, click, click.
Now you might only have a page with backpacks because they are really super rare items. Do you think Google wouldn't notice that the content on the page is just somehow rotated, but has exactly the same content?
If you think that, then you are producing the most beautiful DC with a clear conscience.
3. similar content
Ein wenig ähnlich gelagert wie die Sache mit der Sortierung, aber doch anders. Ihr habt eine Seite mit – ach, sagen wir mal Rucksäcken, diesmal aber eine Detailseite. Der User kann hier Farben auswählen und Ihr liefert eine neue URL aus, weil vielleicht wird der rote Rucksack ja verlinkt und der blaue auch (das wäre toll)?
Well. You may notice that there is hardly any change to the content on the page. The backpack will be blue (because you have a really cool store) and the headline might change.the page looks really different than before!
Well, add up your words, you certainly have a similarity of 99%. Do you think that's enough? - DC.
The most common cases of internal DC
It takes a certain nose for internal duplicate content, precisely because most people don't find it bad and think "Google will fix it and recognize it". Think again. How we deal with duplicate content and control or remove it is explained below.
Here, however, I would like to briefly help you recognize them - just see if you can find one or two problems on your site. I'm deliberately sticking to WordPress topics here, because the Blogosphere as a whole, but the problems are transferable.
- Canonical URL: Is your domain with https://www.domain.de and with https://domain.de, maybe still with https://domain.de/index.php callable?
- IP as a complete DC: Technically, it can also be the case if your IP is in the Index has arrived. Heise, Golem and some other larger sites have this problem. You just have to recognize it and this is usually accidental. But the real problem is: the entire content of the domain is mirrored or duplicated. Not good.
- Useless parameters: Just click on the search button on your WordPress blog without entering a search term. Well? Exactly. Domain-DC/home-page-DC (the worst thing that can happen) - and Google clicks on buttons, we know that.
- Accessibility: Your blog uses tags, categories, date archives, everything that works. Unfortunately, this is all potential DC. Decide on a version of lists that you want to have indexed.
- Article pages under different URLs: Besonders ein WordPress-Problem – Ihr könnt jede URL in Eurem WP-Blog manipulieren. Das macht man natürlich nicht freiwillig, aber vielleicht ändert Ihr unbewusst mal die Kategorie eines Beitrages. Zack, habt Ihr zwei valide URLs, denn – probiert’s mal aus: Ihr könnt den Kategorienamen in der URL durch eine andere Kategorie Eures Blogs ersetzen. Ein falscher Link genügt und Ihr habt DC.
- Grades and selections: The examples from above. Sorted lists and parameterized articles/details pages are DC.
If you look over your pages, you will certainly find DC somewhere, certainly no page here is perfect and be it because of technical restrictions (CMS, blog system, etc.). However, if you know how to recognize DC, you have taken the first really important step towards avoiding it.
Tips and tricks for DC detection
Especially the recognition of similar pages as duplicate content can be a problem. You generally have to think away your navigation, the footer and all that stuff, because Google can do that quite well too. Then compare the remaining text and image elements of the actual content of the two pages in question. If you achieve a value above 80%, you are on the safe side that you have just produced DC. (There are also tools here, such as Sitelinwho calculate such things for you, but it's easiest to do it with reason)
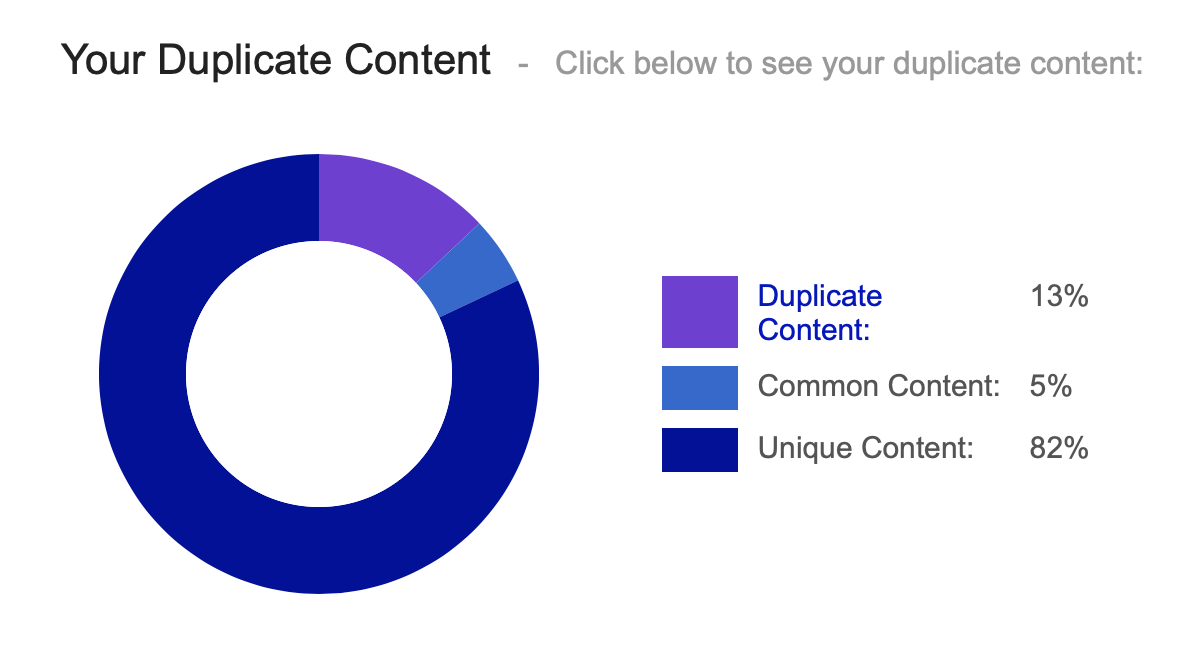
Use Google! Unfortunately, the baby has probably already fallen into the well for this tip. Do a site query of your site and narrow it down so that you should get a solid number of pages. Google indexed now does not include what could be considered a duplicate (near duplicate) or is very similar to other pages on your website. With the query "site:yourpage.com/" you can check all pages that Google has checked and indexed have been, see.

Just assume that anything missing there and not too new potentially has a minor problem.
What is external duplicate content?
External duplicate content refers to duplicate content outside of your own domain. This can be the case both in your own network and on competitors' websites. In my experience, duplicate content on subdomains of your own project is also considered external duplicate content.
"My website looks completely different from the competitor's, I have a different header and footer and other page elements!"
Anyone who approaches the analysis of external DC in this way has lost, and it is precisely this person who should take the following advice very much to heart.
- Google and other search engines recognize page-wide recurring structures such as navigation elements, footer areas or sidebar elements on websites.
- That is, Google can very well distinguish what is content and what is equipment.
So it is really only important to look at the content (in the best case, what is below the H1). Now, anyone who remembers the classification of the first part (internal duplicate content) will recognize the following list in parts.
1. same content on different domains is external duplicate content
That is clear and everyone can understand.
2. similar content on different domains is potential duplicate content
This is also clear when we consider the results of the first part on internal DC. Sorting, lists, results, all of this can mean DC - both internally and externally.
3. your domain is completely duplicated or mirrored
This is by far the nastiest of all issues. If the start page of your product is recognized as DC or appears duplicated on the Internet, you should try to remove the duplicates really quickly. You can see how to proceed to uncover such cases below.
How do search engines react to duplicate content?
Es gibt zwei Möglichkeiten, wie die Suchmaschinen Google, Bing, etc. auf den Duplicate Content reagieren. Entweder die duplizierten Inhalte werden von den Suchmaschinen „zusammengelegt“, oder es kann passieren, dass eine Seite, die sich kopierter Texte bedient, aus dem Index is excluded. Linking the same content with different URLs will worsen the search result.
Search engine optimization professionals therefore strictly ensure that only Unique Content verwendet wird. Es gibt Tools, die fertige Texte auf ihre Einzigartigkeit überprüfen – dazu später mehr. Allerdings reicht es beispielsweise auch, die erste Passage eines Beitrags in Google einzutippen und die Suche zu starten. Findet sich ein ähnlicher Text im World Wide Web, so wird das Ergebnis das auch anzeigen.
Die Texter, die den Auftrag erhalten, Content zu erstellen, sollten eigentlich darauf achten, beziehungsweise überprüfen, ob unique gewährleistet werden kann, oder nicht. Eine Erklärung auf der Rechnung, dass alle Texte aus eigenen Ideen verfasst und nicht abgekupfert wurden, wird von vielen Agenturen in der Suchmaschinenoptimierung verlangt. Es wäre leichtsinnig, Content abzuliefern, der nicht gegengecheckt wurde.
Who owns the original content?
When search engines find duplicate content, they have to decide who owns the original content. They do this according to algorithmic templates, which are basically easy to understand, but the outcome is not always correct or clear.
- Fingerprint/Timestamp: Found content is usually given a kind of versioning by the search engines. This can also be called a fingerprint. It is noted (as everything is always noted everywhere) when the content was found and where. Once this fingerprint has been determined, the page that was first identified with the content is usually assigned the content as the original.
- Google News: I am not an expert in this case, so I can only write superficially. With news, however, you can clearly see that the principle applies: first come, first served. Most newspapers come with DPA reports, which are usually DC, just like press releases (watch out for article directories, press directories, etc.).
- Theft/Content Theft: Content theft is quite problematic. This can be text or images. It's not just yesterday that there were reports of content being stolen and published 1:1 on other sites. This is very annoying, but unfortunately not always avoidable. If the other site is outside the German legal area, there is not much you can do about it legally. However, I will explain small technical things in the next part "Avoiding duplicate content".
- Trust and domain strength: For both fingerprint and stolen content, a good portion of the Trust or the strength of a domain as a factor for the originality of the content. A small example: Your domain with the original content is 3 years old and has various topics. Now someone comes along (perhaps yourself) and takes over this content on a domain that is perhaps 6 years old, has more links and only deals with this topic. The content will probably be attributed to this domain and your own Traffic crashes.
How do I recognize/find external duplicate content?
1. same content on different domains
Such cases can be done very well with a quotation query on Google. Simply take part of the content of your page and copy it into the Google search box "in quotation marks". You may find similar entries that could possibly have a fingerprint. Comparing the date and cache helps with the evaluation. There are also tools that make it possible to track down stolen images or text.
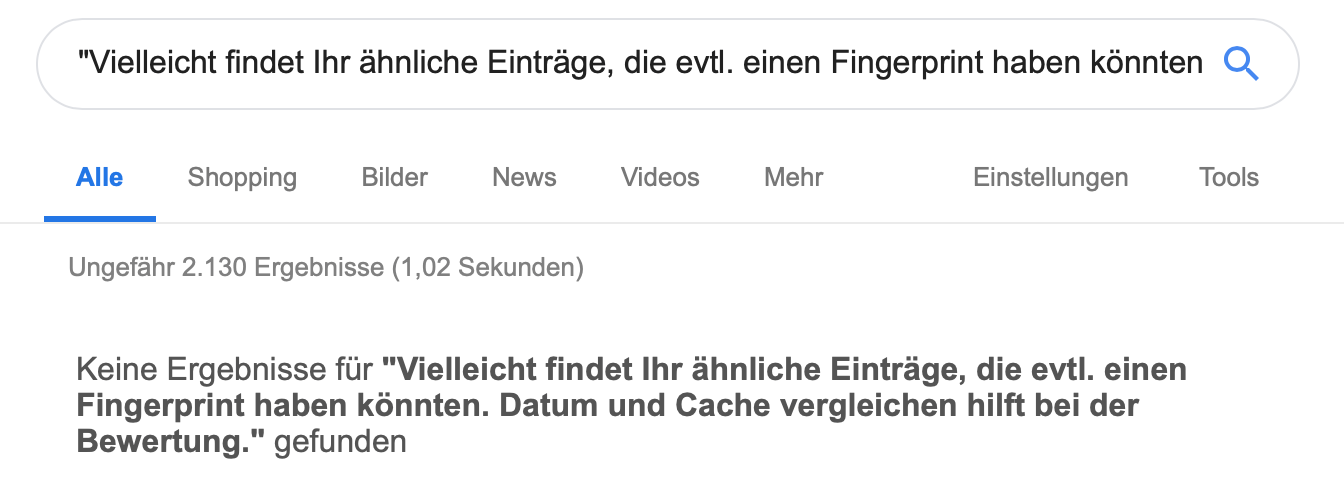
2. similar content on different domains
The typical newspaper/DPA problem. I really can't say much about this because I have some gaps, especially in the news area. In general, however, as with internal DC, the higher the comparability of the text elements, the more likely it is to be DC.
3. duplication of the domain or home page
This is the supergau and you should generally be careful that no duplicates of your home page are sent to you in the Index arrive. Sometimes domains are mirrored, sometimes such things happen because you have an IP in the Index (this is also external DC) and thus mirrors your entire domain. The more Trust and the older the project is, the easier it is for you to get away with such cases. Telekom has tons of domains that have the same content, Heise and similar projects have IPs in the Index and it does no harm (yet). For smaller projects, however, it can certainly be harmful.
You can discover such a duplication by searching for the title of your homepage on Google using the "Intitle query" and taking a closer look at similar pages. I have already written about this problem in more detail and also what you should do if something like this happens.
Prevent internal duplicate content
Wir hatten etwas über gleiche Seiten durch URL-Verwirrung gelesen, , ebenso über ähnliche Seiten und sortierte Listen. Alle dies war bzgl. der Definition, wie wir sie Google in den Mund legen als DC deklariert worden. Diesen gilt es nun zu verhindern und wir haben einige Mittel, die wir nutzen können.
Noindex
In my opinion Noindex the Columbus egg of SEO. Everything you find dubious, everything you don't like, everything you really think is DC - pop a nice "Noindex" tribute on it. The great thing is that any incoming links will at least be redistributed proportionately. So always remember the internal linking denken. Für WordPress gibt es da sehr schöne Tools, wie robots-meta von Yoast oder All In One SEO.
Robots.txt
Mit Eurer robots.txt solltet Ihr vorsichtig umgehen. Denkt immer daran: Alles, was Ihr mittels robots.txt aussperrt, wird vom Bot nicht mehr gefunden. Ihr könnt Euch also ganz schnell den Linkjuice und auch die Crawlability abdrehen. Google findet die Seiten, die von robots.txt gesperrt sind natürlich, denn erst beim Aufrufen weiß der Bot, welche URL the page has.
In principle, no pages that could potentially be linked have a place in robots.txt. You can release individual pages e.g. via Sitemap (Xing does this quite well, you can copy it from there) or wildcards. For testing, however, I strongly recommend going to theGoogle Webmaster Tools to check the correctness, because the wildcards or "allow" are not actually intended in the robots.txt, but they are often needed and are very helpful.
Nofollow
Rel-nofollow is absolutely not helpful to reduce duplicate content. The only thing that will happen is that your links will have no Anchor text and do not pass any Juice. Indexing can be done with nofollow not control. Put that out of your mind. Something else is meta-nofollow. According to the definition here really links are not to be departed. I don't have a test right now, but I don't think that's the case.
Canonical tag
I don't want to give a recommendation here as to whether it's any good, it's still too early for that. Basically, I think the tag is quite suitable for various things. This has mainly to do with redirecting link power from Noindex-Seiten zu tun, die man nicht 301en kann. Ich denke allerdings, dass wir uns hüten sollten, einen zweiten nofollow- oder PageRank-sculpted hype. The tag is too complex for it to be really useful. But I don't need to say that there are different opinions. Testing is the order of the day. But above all:
Set your page structure wisely and profoundly, then you don't need Sculpting or Canonical
Avoid (tracking via) URL parameters
The following often happens on the web: The marketing manager wants to advertise, starts an affiliate program and is happy about the links coming in at the same time. The only pity is that they all generate internal DC for tracking because they are delivered with parameters (e.g. domain.de?afflink=123). There are various solutions here: Cookies and thus track, the parameters noindex set or simply do not track.
SEOmoz showed another great idea: use hash (hash) instead of ?-parameter (i.e. domain.de#afflink=123). If you are interested in this: Here is the Whiteboard Friday video and a nice store example of how you can display pagination with #. The highlight: # is not rated by Google and all the nice link power flows to the original page.
But there are also problems, which can be read in the SEOmoz post. Attention: If you want to make detailed pages accessible with the pagination, make sure that there are not too many links on one page (you have to find out the number yourself, this blog should be able to handle about 100). The example store had no details and therefore works very well with the program.
Well, means are one thing, a few examples are of course much cooler. So here we go.
Category system in WordPress
Well, I briefly touched on this earlier. You often see the same systems in SEO blogs too: Navigation or making the detailed pages accessible via: Tags, author archives, category archives, date archives. What we know from the fingerprint system is that a teaser is almost as good as a detail page. This makes it all the more incomprehensible for me to have the whole jumble of categories and tags and all the rest of it indexed.

With noindex this would be so easy to avoid and after all, the detail pages are what should be important, not just any category. What I find really difficult in this context are systems or plugins that automatically link buzzwords to tag pages. Terrible.
Just to be clear: There are certainly good reasons to have this or that indexed, and in some cases categories can certainly work better than details. What needs to be checked very carefully, however, is the use of several of these archives at the same time. The same also applies to indexable (full) feeds.
You should check the indexing of tag pages in particular. If you have an average of 4-6 tags per post, this means you would potentially have 5 new pages per post in the Index tipping. That is too much.
Duplicate URLs, parameters
Do not have your search pages indexed and redirect your page meinblog.de?s= to your main page, because Google is sure to press a button. Above all, make sure that you create your posts correctly. A big problem with WordPress is that every post in every category can be accessed. This makes you potentially vulnerable from the outside.
If you move a post or want to change your category system in general, you should always create a Plugin like Redirection use. But you should always think about it beforehand, because a 301 can never give you back the link power you have on the original.
Prevent external duplicate content
Avoiding external DC is much more difficult than influencing internal DC, as your influence on the page that provides the external duplicate content is usually beyond your control. Nevertheless, a few basic and simple rules can help you to effectively avoid duplicate content before it is created in many cases.
Organize cooperations
Cooperation partners who play your content for whatever reason (content exchange, playback space, sale, etc.) should at least play the content on noindex setzen. Wenn ein Ausschluss des Crawlings durch die robots.txt machbar ist, sollte auch das getan werden. Externe Kooperationen können gefährlich sein, was DC angeht. Ihr solltet bereits beim Denken daran ganz heftig mit der noindex-Flag waving.
Unique Content
Example: DPA reports. How often do you read the same thing online? And each of these publishers certainly wants to be found online. Unfortunately, there's only one thing that helps most of the time: if you can't publish as quickly as possible, you'll have to resort to real editorial means and change the text.
Fingerprints
What can happen internally with category lists can of course also happen externally. It is usually only worse there, as Google chooses the owner of the original fingerprint itself. The only thing that helps here is Unique Content. If you have partially duplicated content, change it if your time allows and you expect a positive ROI. If neither is the case, close down your site and think about a new task for your web server.
Conclusion on duplicate content
As you can see Noindex really one of my favorites. The meta tag is a powerful tool if you use it correctly. There are certainly other ways to avoid DC, maybe I've forgotten a really important one. You are therefore welcome to comment diligently (provided you have managed to persevere this far).