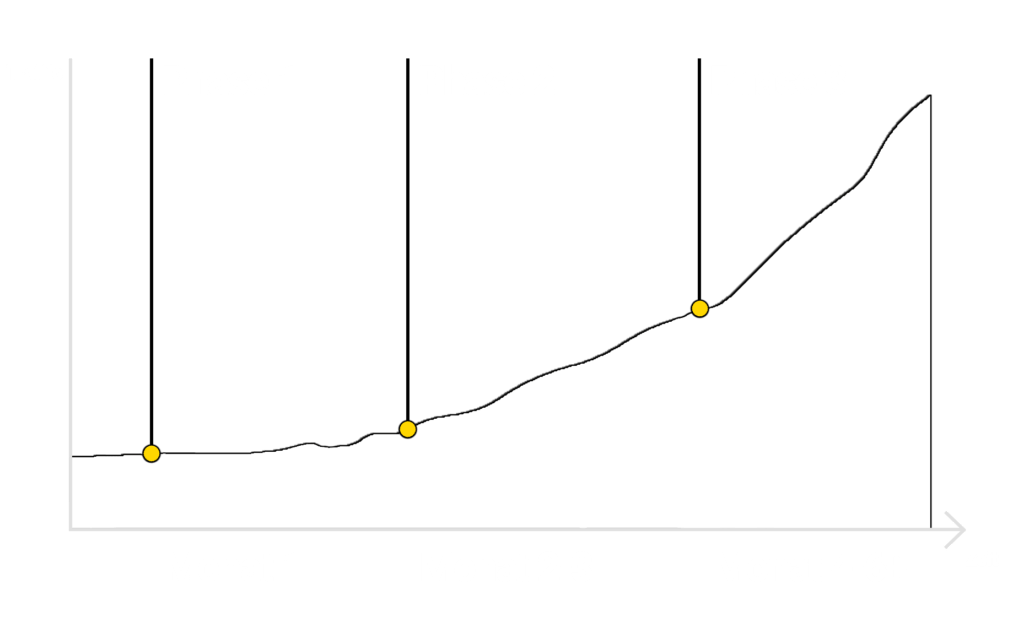
First of all: Super agency, where we get results not only after 6, but already after 2 months.
...could see.
We have been working with Wolf of SEO for 6 months and are very satisfied. The team responds quickly, answers questions competently and has already really brought us forward.
I have already worked with several SEO agencies and the results were often sobering. Every SEO agency says that SEO has to be a long-term project, but if there is no significant success after 6 months, then the agency simply isn't getting it right in my eyes. This was different with Wolf of SEO - we noticed a significant increase in SEO traffic after just 2 months - refreshing
Show more















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}